\(\DeclareMathOperator*{\E}{\mathbb{E}}\) \(\DeclareMathOperator*{\V}{\mathbb{V}}\)
Local level model
One of the simplest state space models is the local level model. Its observation (aka measurement) and state (aka transition) equations are given as
\[\begin{align*} y_t &= x_t + \epsilon_t, \quad \epsilon_t\overset{iid}{\sim}\mathcal{N}(0, \sigma_\epsilon^2),\\ x_t &= x_{t-1} + \eta_t, \quad \eta_t\overset{iid}{\sim}\mathcal{N}(0, \sigma_\eta^2), \end{align*}\]with $t=1,\ldots,n$ and with some initial $x_0\overset{iid}{\sim}\mathcal{N}(a_0, P_0)$. Notice that while the measurements $y_t$ are observed at time $t$, the states $x_t$ are not observed! Given the normality of errors, the model can be rewritten as
\[\begin{align*} y_t &= x_0 + \sum_{i=1}^{t} \eta_i + \epsilon_t, \quad t=1,\ldots,n, \end{align*}\]and solved “brute force” by maximum likelihood. However, due to serial correlation between $y_t$ this approach can become computationally challenging when $n$ gets large. This is especially true for less trivial state space formulations with more parameters. This is where Kalman Filter comes in!
Kalman Filter
KF permits to estimate the unobserved states $x_t$ given the knowledge of the state equation and the observations $y_t$ as they come in. In fact, KF uses these two sources of information iteratively: at $t-1$, KF uses the state equation to predict the state with $\widehat{x}_ {t\mid t-1}$ and at $t$, once $y_t$ is observed, KF updates the estimate $\widehat{x} _{t\mid t}$ with new measurement information. In parallel, KF also updates and predicts the error associated with the state equation projections – this is necessary to balance off the trust between the two sources of information, state equation prediction vs measurement update.
Some notation
\[\begin{align*} \widehat{x}_{k|l} &:= \E(x_k|I_{l}),\\ \widehat{v}^2_{k|l} &:= \V(x_k|I_{l}), \end{align*}\]where $k,l \in [1,\ldots, n]$.
The prediction step simply computes the conditional mean and variance of $x_t$
\[p(x_t|I_{t-1}) \sim \mathcal{N}(\widehat{x}_{t|t-1}, \widehat{v}^2 _{t|t-1}),\]which can readily be computed based on the state equation
\[\begin{align*} \widehat{x}_{t|t-1} &= \E(x_t|I_{t-1}) = \E(x_{t-1} + \eta_t|I_{t-1}) = \widehat{x}_{t-1|t-1},\\ \widehat{v}^2_{t|t-1} &= \V(x_t|I_{t-1}) = \V(x_{t-1} + \eta_t|I_{t-1}) = \widehat{v}^2_{t-1|t-1} + \sigma_\eta^2. \end{align*}\]The above equations solely leverage the state transition equations to predict where the state might be at time $t$. But then, at time $t$, $y_t$ comes in – how do we update our knowledge about the state once we observe this new measurement?
From a Bayesian perspective, the state prediction estimate forms a prior while the incoming measurement observation lets us define the likelihood. Hence, the update step yields a posterior estimate.
\[\begin{align*} p(x_t|I_{t}) = p(x|y_t, I_{t-1}) & = \frac{p(y_t|x_t, I_{t-1}) p(x_t|I_{t-1})}{p(y_t|I_{t-1})}\\ & \propto p(y_t|x_t, I_{t-1}) p(x_t|I_{t-1})\\ & = \mathcal{N}(x_t, \sigma_\epsilon^2) \times \mathcal{N}(\widehat{x}_{t|t-1}, \widehat{v}^2_{t|t-1})\\ & = c_0 \; e^{-\frac{1}{2}\left(\frac{y_t-x_t}{\sigma_\epsilon}\right)^2} e^{-\frac{1}{2}\left(\frac{x_t-\widehat{x}_{t|t-1}}{\widehat{v}^2_{t|t-1}}\right)^2} \end{align*}\]Oops, product of Gaussians.
Fun Fact.
The product of two Gaussian is a scaled Gaussian:
\(\frac{1}{\sqrt{2\pi}\sigma_1} e^{-\left({\frac{x-\mu_1}{\sigma_1}}\right)} \times
\frac{1}{\sqrt{2\pi}\sigma_2} e^{-\left({\frac{x-\mu_2}{\sigma_2}}\right)} = c' \times e^{-\left({\frac{x-\mu'}{\sigma'}}\right)^2},\)
where
\(\mu' = \mu_1 + \left(\frac{\sigma^2_1}{\sigma^2_1 + \sigma^2_2}\right)(\mu_2 -\mu_1), \quad \sigma'^2 = \left(1-\frac{\sigma^2_1}{\sigma^2_1 + \sigma^2_2}\right) \sigma_1^2.\)
Hence we can rewrite the above density as
\[p(x_t|I_{t}) = c_1 \; e^{-\frac{1}{2}\left(\frac{x_t - x_{t|t}}{\widehat{v}^2_{t|t}}\right)^2},\]with the following equations defining the update step
\[\begin{align*} \widehat{x}_{t|t} &= \widehat{x}_{t|t-1} + \left(\frac{\widehat{v}^2_{t|t-1}}{\widehat{v}^2_{t|t-1} + \sigma_\epsilon^2}\right) \left(y_t -\widehat{x}_{t|t-1}\right),\\ \widehat{v}^2_{t|t} &= \left(1-\frac{\widehat{v}^2_{t|t-1}}{\widehat{v}^2_{t|t-1} + \sigma_\epsilon^2}\right) \widehat{v}^2_{t|t-1}. \end{align*}\]Kalman gain
The term $k _t := \frac{\widehat{v}^2 _{t\mid t-1}}{\widehat{v}^2 _{t\mid t-1} + \sigma _\epsilon^2}$ is known as Kalman gain. Notice how it balances the information coming from state and measurement signals: if the measurement noise $\sigma _\epsilon^2$ is high, Kalman gain $k _t$ is small, and hence the update equations will place more weight on the information coming from the state transition equations.
Putting everything together, the KF equations for the above local linear model are
Notice the dynamics of uncertainty over time: the state estimate uncertainty $\widehat{v}^2$ increases with each prediction but decreases every time the measurement is observed.
No data – no problem
One of the nicest things about state space models & KF is that the missing data problem is handled naturally. If no $y_t$ is brought in at $t$, one can omit the update step. Then the estimate would be solely determined by the “model”, i.e. by its state transition prediction. From a bayesian standpoint, our posterior estimate is set equal to the prior as no likelihood can be formed.
More general case
We have an $N\times 1$ vector $\mathrm{y}_t$ and an $m\times 1$ state vector $\mathrm{x}_t$. A general state space model can be specified as follows
\[\begin{align*} \mathrm{y}_t & = Z_t \mathrm{x}_t + d_t + \varepsilon_t, \\ \mathrm{x}_{t+1} & = T_t \mathrm{x}_t + c_t + R_t \eta_t, \\ \varepsilon_t & \overset{iid}{\sim} \mathcal{N}(0, H_t), \\ \eta_t & \overset{iid}{\sim} \mathcal{N}(0, Q_t), \end{align*}\]where $Z_t$ is an $N\times m$ design matrix, $T_t$ is an $m\times m$ transition matrix and $R_t$ is an $m\times g$ selection matrix. Further, it is often assumed that the two errors are uncorrelated
\[\begin{equation*} \E(\varepsilon_t \eta_s') = 0, \; \forall t,s = 1,\ldots,T. \end{equation*}\]State space modeling is fairly general as several approaches can be formulated in this form, including SARIMAX, VARMAX, unobserved components, factor models, linear exponential smoothing models, etc.
AR(2) Model
An AR(2) model
\[\begin{equation*} \mathrm{y}_t = \phi_1 y_{t-1} + \phi_2 y_{t-2} + \epsilon_t, \quad \epsilon_t \sim N(0, \sigma^2) \end{equation*}\]can be cast into state space form in several ways. For example,
\[\begin{align*} \mathrm{y}_t & = \begin{pmatrix} 1 & 0 \end{pmatrix} \mathrm{x}_t, \\ \mathrm{x}_{t+1} & = \begin{pmatrix} \phi_1 & \phi_2 \\ 1 & 0 \end{pmatrix} \mathrm{x}_t + \begin{pmatrix} 1 \\0\end{pmatrix} \eta_t, \end{align*}\]where \(\mathrm{x}_t = \begin{pmatrix} \mathrm{y}_t \\ y_{t-1}\end{pmatrix}\) and we let
\[\begin{align*} \begin{split} Z_t & = Z = \begin{pmatrix} 1 & 0 \end{pmatrix} \\ T_t & = T = \begin{pmatrix} \phi_1 & \phi_2 \\ 1 & 0 \end{pmatrix} \\ R_t & = R = \begin{pmatrix} 1 \\ 0 \end{pmatrix} \\ \eta_t & = \epsilon_{t+1} \sim N(0, \sigma^2) \end{split} \end{align*}\]and so we have three parameters to estimate: $\phi_1, \phi_2, \sigma^2$.
MA(1) Model
An MA(1) model
\[\begin{equation*} \mathrm{y}_t = \nu_t + \theta \nu_{t-1}, \end{equation*}\]can be cast as
\[\begin{align*} \mathrm{y}_t & = \begin{pmatrix} 1 & 0 \end{pmatrix} \mathrm{x}_t, \\ \mathrm{x}_{t+1} & = \begin{pmatrix} 0 & 1 \\ 0 & 0 \end{pmatrix} \mathrm{x}_t + \begin{pmatrix} 1 \\ \theta \end{pmatrix} \eta_t, \end{align*}\]where \(\mathrm{x}_t = \begin{pmatrix} \mathrm{y}_t \\ \theta \nu_t \end{pmatrix}\).
ARMA(1,1) Model
An ARMA(1,1) model
\[\begin{equation*} \mathrm{y}_t = \phi y_{t-1} + \nu_t + \theta \nu_{t-1}, \end{equation*}\]can be cast as
\[\begin{align*} \mathrm{y}_t & = \begin{pmatrix} 1 & 0 \end{pmatrix} \mathrm{x}_t, \\ \mathrm{x}_{t+1} & = \begin{pmatrix} \phi & 1 \\ 0 & 0 \end{pmatrix} \mathrm{x}_t + \begin{pmatrix} 1 \\ \theta \end{pmatrix} \eta_t, \end{align*}\]where \(\mathrm{x}_t = \begin{pmatrix} \mathrm{y}_t \\ \theta \nu_t \end{pmatrix}\).
General Update & Prediction
Letting \(\widehat{\mathrm{x}}_{k\mid l} := \E(\mathrm{x}_k\mid I_{l})\) and \(P_{k\mid l} := \V(\mathrm{x}_k\mid I_{l})\)
Example & Code
Notation change alert!
Consider another specification as given in wikipedia.
\[\begin{align*} \mathrm{z}_t & = H_t \mathrm{x}_t + \mathrm{v}_t, \\ \mathrm{x}_{t} & = F_t \mathrm{x}_{t-1} + B_t \mathrm{u}_t + \mathrm{w}_t, \\ \mathrm{v}_t & \overset{iid}{\sim} \mathcal{N}(0, R_t), \\ \mathrm{w}_t & \overset{iid}{\sim} \mathcal{N}(0, Q_t), \end{align*}\]The KF solution script is stolen from given in here.
class KalmanFilter(object):
def __init__(self, F = None, B = None, H = None, Q = None, R = None, P = None, x0 = None):
if(F is None or H is None):
raise ValueError("Set proper system dynamics.")
self.n = F.shape[1]
self.m = H.shape[1]
self.F = F
self.H = H
self.B = 0 if B is None else B
self.Q = np.eye(self.n) if Q is None else Q
self.R = np.eye(self.n) if R is None else R
self.P = np.eye(self.n) if P is None else P
self.x = np.zeros((self.n, 1)) if x0 is None else x0
def predict(self, u = 0):
self.x = np.dot(self.F, self.x) + np.dot(self.B, u)
self.P = np.dot(np.dot(self.F, self.P), self.F.T) + self.Q
return self.x
def update(self, z):
y = z - np.dot(self.H, self.x)
S = self.R + np.dot(self.H, np.dot(self.P, self.H.T))
K = np.dot(np.dot(self.P, self.H.T), np.linalg.inv(S))
self.x = self.x + np.dot(K, y)
I = np.eye(self.n)
self.P = np.dot(np.dot(I - np.dot(K, self.H), self.P),
(I - np.dot(K, self.H)).T) + np.dot(np.dot(K, self.R), K.T)
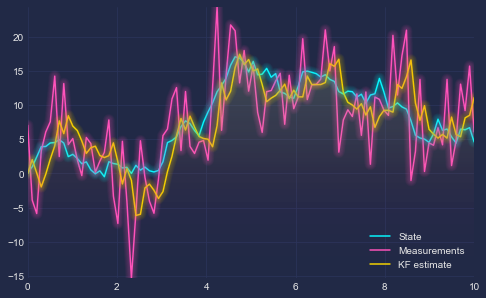
Suppose we make the data generating process look like
\[\begin{align*} y_t &= x_t + \epsilon_t, \quad \epsilon_t\overset{iid}{\sim}\mathcal{N}(0, 5),\\ x_t &= x_{t-1} + \eta_t, \quad \eta_t\overset{iid}{\sim}\mathcal{N}(0, 1), \end{align*}\]for $t=1,\ldots,100$ and try to estimate the simple local level model we started with at the beginning
F = np.array([1]).reshape(1, 1)
H = np.array([1]).reshape(1, 1)
Q = np.array([1]).reshape(1, 1)
R = np.array([5]).reshape(1, 1)
# DGP
time = np.linspace(0, 10, 100)
x = np.zeros(100)
for t in range(99):
x[t+1] = x[t] + np.random.normal(0, 1)
measurements = x + np.random.normal(0, 5, 100)
kf = KalmanFilter(F = F, H = H, Q = Q, R = R)
predictions = []
for z in measurements:
predictions.append(np.dot(H, kf.predict())[0])
kf.update(z)
plt.plot(time, x, label = 'State')
plt.plot(time, measurements, label = 'Measurements')
plt.plot(time, np.array(predictions), label = 'KF estimate')
plt.legend()
plt.show()
We get the following result